
Come Google rileva i contenuti generati dall’IA
Hai visto questo post su LinkedIn di Geoff Kenyon? Parla di una cosa che quasi nessuno conosce: una specie di firma invisibile che Google infila in ogni contenuto creato con la sua IA.
Il testo dice:
How much do you know about Google’s invisible watermarking they put on images, text, video, and audio files that Gemini / Vertex AI generates? It’s called SynthID.If you’re using AI in your content / asset generation process, this is probably helpful to understand SynthID (and inherently how invisible watermarking works). Think about this:
If LLMs can fingerprint their own content and detect other AI generated content, why would they cite your AI content instead of another resource that is more likely human created?
Similarly, why would Google surface LLM generated content in organic results when they could force users into AI Mode instead (think Google flights, maps, local, etc).
SynthID is an undetectable pattern woven into the pixel data during generation. It survives cropping, compression, screenshots, and a lot of editing. The pixels in the pattern have color values slightly shifted from what they would otherwise be imperceptible to humans, but a noticeable pattern for machines.
Google even declares it in the EXIF metadata: “Created by Google Generative AI. Applied imperceptible SynthID watermark. But that metadata gets stripped by screenshots and social platforms. The pixel-level watermark survives.
I lied to you a little – you can actually see this watermark under some conditions. If we isolate the specific frequencies where SynthID exists and saturate, the pattern becomes vivid and evident. The image here shows a Gemini-generated plain white square that has isolated the frequencies for SynthID and then increased the contrast 1000x.
What’s old is new. Spintax was machine generated content that worked until Google could detect it at scale. SynthID is Google’s detection infrastructure for the AI content era.
For GEO, LLMs training on AI-generated content creates a circular feedback loop, sometimes called model collapse. Watermarking like SynthID (OpenAI and Meta have their own watermarking research programs) gives models a way to filter AI generated content out of future training sets at scale.
I’m not saying don’t create content with AI, but before you go all in on AI content, you should understand this and mitigate risk accordingly. If you’re taking the easy path now, it might work for a while, but looking at the long arc of SEO, it will certainly stop working at some point.
Non stiamo parlando di metadati che cancelli in un clic o di un’etichetta banale. È qualcosa di integrato proprio dentro al contenuto.
Guarda qui come appare questo segno nascosto:
![]()
La tecnologia si chiama SynthID e Google non è l’unica a usarla.
Cos’è SynthID?
In pratica è un watermark digitale creato da Google DeepMind. Viene inserito mentre l’IA genera testo, immagini o video. Tu non lo vedi, la qualità non cambia, ma i software lo leggono subito.
È un po’ come un numero di serie tatuato sul contenuto appena nasce. Invisibile per noi, chiarissimo per le macchine.
Siamo già a cifre enormi: nel 2026, più di 10 miliardi di file avevano già questo marchio.
Lo trovi ovunque negli strumenti Google:
- Gemini per i testi,
- Imagen per le foto,
- Lyria per la musica,
- e Veo per i video.
Comunque, non c’è solo Google. Oltre 200 colossi come Microsoft, Adobe e OpenAI si sono uniti nella coalizione C2PA.
Hanno creato le Content Credentials, una sorta di “etichetta degli ingredienti” digitale che dice chi ha fatto cosa e se c’è lo zampino dell’IA.
OpenAI le usa già per tutto quello che esce da ChatGPT e DALL·E.
Si possono togliere questi watermark?
Qui viene il bello. Se tagli una foto, la comprimi o ci metti un filtro, il marchio resta lì. Nei video è ancora peggio: ogni singolo frame è segnato, quindi non scappi nemmeno tagliando le clip.
Il segreto è che non sono dati “appiccicati” sopra, ma sono parte integrante del file. Se isoli certe frequenze di pixel e alzi il contrasto, la firma viene fuori. C’era dall’inizio, dovevi solo sapere dove guardare.
Certo, se distruggi l’immagine con modifiche pesantissime forse lo rovini, ma a quel punto rovini anche il contenuto.
Per i testi invece, se riscrivi tutto da zero o traduci seriamente, il watermark perde colpi, ma non è così immediato come sembra.
C’è un trucco anche per i testi?
Ebbene sì. Quando un’IA scrive, sceglie una parola alla volta in base a quanto è probabile che venga dopo. SynthID modifica leggermente queste probabilità per creare uno schema specifico.
È questo schema la filigrana. Un rilevatore lo confronta con i testi standard e capisce subito se c’è il “tocco” dell’intelligenza artificiale.
Funziona alla grande sui testi lunghi, mentre sulle frasi brevi (tipo “qual è la capitale della Francia?”) fa più fatica perché c’è poco margine di manovra.
Storia che si ripete
Chi fa SEO da tempo si ricorderà dello Spintax, quei software che frullavano sinonimi per fregare Google.
Ha funzionato per un po’, poi Google ha imparato il trucco e fine dei giochi.
Ogni volta che una scorciatoia smetteva di funzionare, non era perché Google avesse deciso improvvisamente di punire i singoli, ma perché l’infrastruttura di rilevamento si era silenziosamente evoluta.
SynthID rappresenta l’infrastruttura di controllo per l’era dei contenuti generati dall’intelligenza artificiale. Questo non implica che tali contenuti vengano penalizzati oggi; tuttavia, l’evoluzione storica della SEO segue un percorso coerente: gli stessi strumenti che facilitano la produzione di massa tendono a sviluppare le tecnologie necessarie a neutralizzarne gli abusi.
Ma perché a Google interessa così tanto?
Non è solo per darti una penalità. Il vero rischio è il “collasso del modello”.
Le IA imparano da quello che trovano online.
Se internet si riempie di roba generata da IA, i modelli futuri studieranno su se stessi invece che su testi umani.
Nature spiega che questo crea un corto circuito: le IA iniziano a dimenticare le sfumature umane e diventano banali o sparano cavolate assurde.
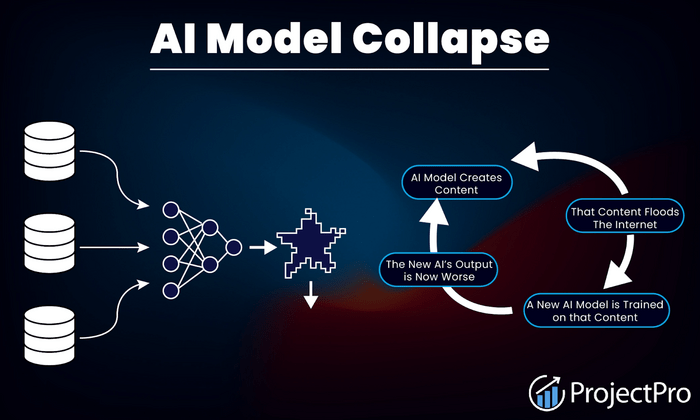
Fonte: https://www.projectpro.io/article/ai-model-collapse/1177
In un esperimento, i ricercatori hanno perfezionato un modello linguistico utilizzando esclusivamente dati generati da altre intelligenze artificiali.
I risultati sono stati emblematici: già alla quarta generazione di riaddestramento, un modello istruito per discutere di architettura medievale ha iniziato a produrre testi completamente fuori contesto riguardanti le lepri.
Questo fenomeno è un esempio concreto di collasso del modello, un processo in cui l’IA perde progressivamente il contatto con la realtà dei dati originali.
Identificare cosa è IA serve a Google per “pulire” i dati con cui addestra i suoi futuri cervelloni. Ecco perché hanno reso SynthID open source: vogliono che tutti lo usino per tenere traccia di cosa è vero e cosa no.
Questa è la tua tabella di marcia editoriale ed è ciò che distingue i contenuti strategici dalle semplici supposizioni.
1. Definisci la tua nicchia prima di scrivere
I contenuti generici vengono facilmente individuati e ignorati proprio perché privi di una voce distintiva.
L’antidoto a questa omologazione consiste nel conoscere a fondo il proprio settore, così da individuare angoli di visuale inediti che nessun altro sta esplorando.
Solo attraverso una specializzazione profonda è possibile produrre valore che l’intelligenza artificiale non può replicare basandosi su medie statistiche.
2. Rendere l’IA uno strumento di ricerca e di stesura, non l’autore
Utilizza l’intelligenza artificiale per raccogliere informazioni preliminari, generare schemi logici e velocizzare la stesura delle prime bozze.
In un secondo momento, aggiungi ciò che solo tu puoi offrire: un punto di vista controcorrente, un caso di studio tratto dalla tua esperienza diretta, dati originali o un’osservazione specifica del tuo settore che non sia già presente nei risultati di ricerca.
Questo valore aggiunto rappresenta l’unico elemento che i sistemi di rilevamento non possono replicare, semplicemente perché non esisteva prima che tu lo scrivessi.
3. Aggiungere, ove possibile, dati originali o esperienze dirette.
Una ricerca dell’Università di Princeton ha dimostrato che l’integrazione di statistiche originali e citazioni verificate può aumentare la probabilità di essere citati dai sistemi di intelligenza artificiale del 30-40%.
La logica sottostante è lineare: i modelli IA prediligono dati estraibili e verificabili.
Mentre un testo generico non offre spunti di riferimento, un sondaggio proprietario, un caso studio o un dato calcolato forniscono gli elementi necessari per alimentare le risposte sintetiche.
Cosa funziona meglio secondo la ricerca
- Stando ai dati emersi, l’efficacia delle diverse strategie si suddivide in questo modo:
- Integrazione di statistiche e dati: porta a un miglioramento della visibilità IA del 40%. I contenuti con numeri specifici e percentuali vengono rilevati con una frequenza nettamente superiore.
- Inserimento di citazioni autorevoli: garantisce un incremento del 28%. Le parole di esperti conferiscono ai modelli la credibilità necessaria per validare le informazioni.
- Strategie combinate: l’adozione congiunta di citazione delle fonti e dati statistici migliora la visibilità complessiva del 30-40% rispetto ai valori standard.
- La combinazione vincente: l’ottimizzazione della fluidità del testo unita all’aggiunta di statistiche supera ogni singola strategia di oltre il 5,5%.
Questo schema spiega perché piattaforme come Wikipedia o Reddit dominano le risposte di ChatGPT e le panoramiche IA di Google: non è solo merito del posizionamento tradizionale, ma della presenza di risposte specifiche e concrete fornite dagli utenti.
L’originalità dei dati batte sempre la rielaborazione di contenuti esistenti.
4. Evita di usare i rilevatori IA come unica garanzia
Mentre analizzi queste strategie, potresti essere tentato di sottoporre i tuoi testi a un rilevatore e considerare il lavoro concluso.
Tuttavia, questo non è un metodo affidabile per garantire la qualità o l’originalità del contenuto.
Strumenti come GPTZero, Turnitin e Originality.ai offrono risultati spesso contrastanti.
Uno studio del 2023 sottoposto a revisione paritaria, che ha testato 14 tra i rilevatori più popolari, ha evidenziato come nessuno di essi raggiungesse l’80% di accuratezza. In diversi casi, testi scritti interamente da esseri umani sono stati erroneamente segnalati come generati dall’intelligenza artificiale. Persino OpenAI ha lanciato un proprio classificatore, decidendo di ritirarlo dopo pochi mesi a causa della sua inefficacia.
Puoi utilizzare questi strumenti per una verifica superficiale, ma un punteggio positivo non deve mai essere considerato un via libera definitivo.
5. Costruire un’identità d’autore coerente
Le linee guida EEAT di Google hanno sempre premiato la competenza dimostrabile, ma oggi la loro rilevanza è centrale.
Una firma associata a un profilo reale (pubblicazioni precedenti, una pagina autore con credenziali verificate e uno stile coerente) segnala qualcosa che un rilevatore tecnico non può misurare: l’esperienza pertinente dell’autore.
Lista di controllo pratica per l’autorità
Attribuzione chiara: ogni opera deve indicare esplicitamente l’autore.
- Biografia strutturata: inserisci link a lavori pubblicati su LinkedIn, testate di settore o siti personali.
- Pagina autore dedicata: crea una sezione sul tuo sito che certifichi chiaramente la tua area di competenza.
- Coerenza editoriale: mantieni un tono e una prospettiva unici, che rendano il contributo insostituibile rispetto ad altri membri del team.
Questo approccio è fondamentale ben oltre il semplice posizionamento.
I sistemi di intelligenza artificiale che estraggono citazioni privilegiano fonti verificabili: un’affermazione attribuita a un generico “redattore” ha meno valore della stessa informazione fornita da un esperto con una storia documentata nel settore.
6. Oltre il rilevamento: le tattiche grey-hat
Alcuni team di lavoro si spingono oltre la semplice modifica superficiale, impegnandosi attivamente per ridurre la rilevabilità delle filigrane digitali.
La documentazione tecnica conferma l’efficacia di questi metodi, sebbene con diversi gradi di successo:
- Riscrittura strutturale profonda: rielaborare a fondo il testo generato dall’IA, non limitandosi alla sostituzione di sinonimi ma intervenendo sulla struttura e sull’ordine delle frasi, riduce significativamente l’affidabilità di SynthID.
Sostituire “importante” con “significativo” lascia intatto lo schema dei token sottostante; ristrutturare l’esposizione delle idee, al contrario, lo altera profondamente. - Traduzione bidirezionale (back-translation): tradurre un testo in un’altra lingua per poi ritradurlo in quella originale può compromettere la rilevabilità della filigrana, poiché il processo rigenera la sequenza di token.
Uno studio accademico del 2025 ha evidenziato che la traduzione inversa è una delle vulnerabilità principali di SynthID, con un calo drastico della precisione di rilevamento. - Elaborazione tramite modelli alternativi: elaborare l’output di un modello (come Gemini) attraverso un’intelligenza artificiale differente e priva dello stesso watermark (come Claude o Llama) produce una sequenza di token completamente nuova.
In questo modo, il segnale di SynthID non sopravvive perché il contenuto viene rigenerato anziché semplicemente modificato.
Queste tattiche riducono la tracciabilità, ma non rendono il contenuto più utile o degno di essere citato. Superare un controllo anti-tracciamento e produrre valore reale sono due sfide distinte: la seconda resta la più difficile da aggirare.
…e quindi ?
Un buon contenuto SEO si è sempre basato su un unico elemento: una persona reale con un punto di vista autentico.
SynthID e gli altri sistemi di rilevamento basati sull’intelligenza artificiale non cambiano le regole del gioco.
Semplicemente, rendono più facile capire chi stia effettivamente partecipando.
Share this article
Ultimi articoli

Luglio 23, 2026

Luglio 23, 2026

Luglio 23, 2026
